ServicePulse is unable to connect to ServiceControl
- Verify that ServicePulse is trying to access the correct ServiceControl URI (based on ServiceControl instance URI defined in ServicePulse installation settings).
- Check that ServicePulse is not blocked from accessing the ServiceControl URI by firewall settings.
- Ensure that Authentication is correctly configured in ServiceControl, allowing CORS access to the ServicePulse URL.
ServicePulse reports empty failed message groups
RavenDB's index could be disabled. This typically happens when disk space runs out. To fix this:
- Provision or free up disk space.
- If running on Windows:
- Put ServiceControl in maintenance mode.
- Open the Raven Studio browser. This assumes ServiceControl is using the default port and host name; adjust the url accordingly if this is not the case.
- If running in a container:
- Follow the container RavenDB access instructions
- Navigate to the Indexes tab
- For each disabled index, set its state to Normal.
ServicePulse doesn't load successfully after an update
There may be previous versions of assets cached by the browser after updating ServicePulse. These previous versions could conflict with the latest versions resulting in an error at startup which would cause ServicePulse not to progress beyond the loading icon. To resolve this issue, clear the browser cache and refresh the page again.
Heartbeat failure in ASP.NET (IIS hosting) applications
Scenario
After a period of inactivity, a web application endpoint is failing with the message:
Endpoint has failed to send expected heartbeat to ServiceControl. It is possible that the endpoint could be down or is unresponsive. If this condition persists restart the endpoint.
When accessed, the web application is operating as expected. However, shortly after accessing the web application, the heartbeat message is restored and indicates the endpoint status as active.
Causes and solutions
The issue is due to the way IIS handles application pools. By default, after a certain period of inactivity, the application pool is stopped or, under certain configurable conditions, the application pool is recycled. In both cases the ServicePulse heartbeat is not sent anymore until a new web request comes in waking up the web application.
To avoid the issue, configure IIS to keep the application pool alive:
- Enable AlwaysRunning mode for the application pool of the site. Go to the application pool management section, open the Advanced Settings, and in the General settings switch
Start ModetoAlwaysRunning. - Enabled Preload for the site itself. Right click on the site, then Manage Site in Advanced Settings, and in the General settings switch
Enable Preloadtotrue. - Install the Application Initialization Module.
- Add the following to the web.config in the system.webServer node.
This approach also has the benefit of avoiding the "first user after idle time" wake-up response-time hit.
<applicationInitialization doAppInitAfterRestart="true" >
<add initializationPage="/" />
</applicationInitialization>
IIS versions prior to v7.5 do not support the Application Initialization Module. It is recommended to run on the latest version of IIS; however, if this is not possible then one of the following strategies will achieve the same effect:
- manually setting the application pool recycling interval to 0
- creating an application that calls a HTTP GET on the application pool at least every 20 minutes (the default IIS recycle-on-idle time).
Duplicate endpoints appear in ServicePulse after re-deployment
This may occur when an endpoint is re-deployed or updated to a different installation path (a common procedure by deployment managers like Octopus deploy).
The installation path of an endpoint is used by ServiceControl and ServicePulse as the default mechanism for generating the unique Id of an endpoint. Changing the installation path of the endpoint affects the generated Id, and causes the system to identify the endpoint as a new and different endpoint.
To address this issue, Override the host identifier to ensure it remains static between deployments.
Saga Audit plugin needed message seen in "Saga Diagram' tab
If the message is part of a saga but the saga audit plugin is not installed, ServicePulse will display a notification with instructions to install it.
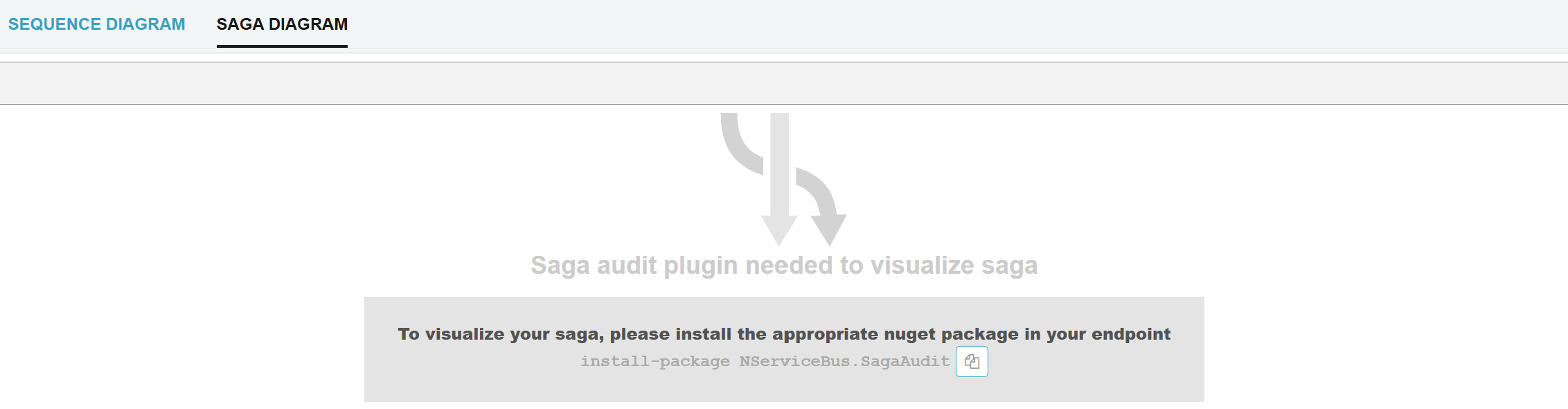
To address this issue:
Install the NServiceBus.SagaAudit package in the relevant endpoint:
install-package NServiceBus.SagaAuditConfigure the saga audit feature in your endpoint configuration:
endpointConfiguration.AuditSagaStateChanges( serviceControlQueue: "particular.servicecontrol");Restart the endpoint to apply the changes
Note that only new saga updates will be captured, not historical ones
Saga state changes are not visible in the "Saga Diagram' tab
Sometimes messages that are part of the saga may not have any state changes visible in saga updates.
This is normal for messages that don't modify the core business state of the saga. This could mean that the incoming message didn't modify any saga properties and/or that only NServiceBus system properties (Id, Originator, OriginalMessageId) were modified, since these properties are filtered out of the view. If the message triggered any outgoing messages or timeouts then it will show state changes in the Saga Diagram.